Crawl Budget Optimisation: Help Google Crawl Your Important Pages
What Is Crawl Budget and Why It Matters
Crawl budget is the number of pages Googlebot will crawl on your site within a given timeframe. For small sites with a few hundred pages, crawl budget is rarely a concern — Google will find and index everything without issue. But for sites with thousands or millions of URLs, crawl budget optimisation becomes a critical discipline that directly affects which pages appear in search results and how quickly changes get picked up.
Google has explicitly stated that crawl budget is primarily a concern for large sites, but that threshold is lower than many practitioners assume. E-commerce sites with faceted navigation, media publishers with extensive archives, and enterprise platforms with dynamic URL parameters can exhaust crawl budget long before they reach the million-page mark. In the Singapore market, where many businesses operate multi-language sites (English, Mandarin, Malay, Tamil) with region-specific content, URL proliferation happens faster than expected.
The practical consequence of wasted crawl budget is straightforward: if Googlebot spends its allocated crawling time on low-value or duplicate pages, your important pages — product listings, service pages, fresh content — get crawled less frequently. This delays indexing of new content, slows the pickup of on-page changes, and can prevent deep pages from being indexed entirely.
As part of a broader SEO strategy, crawl budget optimisation sits at the technical foundation. You can produce excellent content and build strong backlinks, but if Google cannot efficiently discover and crawl your pages, the rest of the SEO stack underperforms.
Crawl Rate Limit vs Crawl Demand
Google defines crawl budget through two components: crawl rate limit and crawl demand. Understanding how these interact is essential before implementing any optimisations.
Crawl Rate Limit
The crawl rate limit is the maximum number of simultaneous connections Googlebot will use to crawl your site, along with the delay between requests. Google sets this automatically based on your server’s response capacity. If your server responds quickly and without errors, Google increases the crawl rate. If your server slows down, returns 500 errors, or times out, Google backs off aggressively.
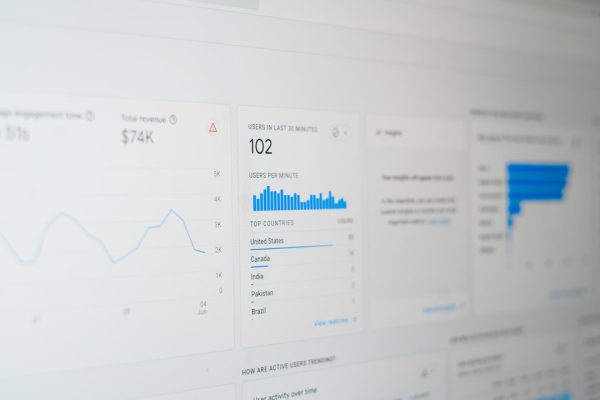
You can observe your crawl rate limit in Google Search Console under Settings > Crawl stats. The crawl requests graph shows how many pages Google is requesting per day. A sudden drop in crawl activity often indicates server-side issues that triggered a rate reduction.
Crawl Demand
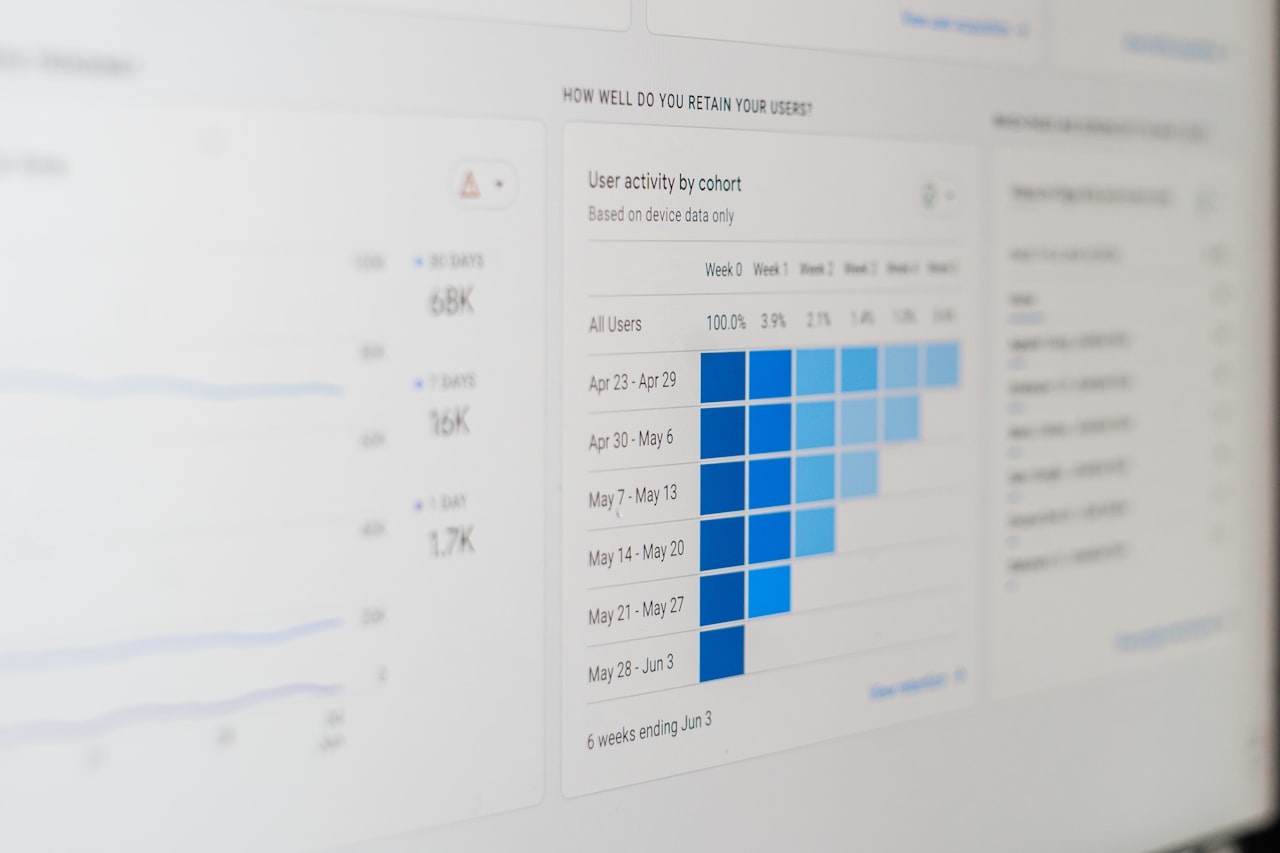
Crawl demand reflects how much Google wants to crawl your site. Pages that are popular (have strong backlinks, receive traffic), pages that are updated frequently, and newly discovered URLs all generate higher crawl demand. Stale, low-authority pages generate minimal demand.
The effective crawl budget is the lower of these two values. Even if your server can handle 10,000 requests per day, if Google only has demand to crawl 2,000 pages, your effective budget is 2,000. Conversely, high-demand sites with slow servers are bottlenecked by the rate limit.
Why Both Components Matter
Many SEO practitioners focus exclusively on the demand side — trying to make pages more important so Google crawls them more. But server-side improvements often deliver faster, more measurable results. Reducing server response time from 800ms to 200ms can double or triple your effective crawl rate within weeks, with no content changes required.
Diagnosing Crawl Budget Waste
Before optimising, you need to identify where your crawl budget is being wasted. The primary diagnostic tools are server log analysis, Google Search Console crawl stats, and site auditing tools.
Google Search Console Crawl Stats
The crawl stats report in Search Console provides a high-level view of Googlebot’s activity. Key metrics to examine include total crawl requests per day, average response time, and the breakdown of response codes. A healthy crawl profile shows predominantly 200 responses with minimal 301s, 404s, and 500s.
Pay close attention to the “purpose” breakdown: discovery crawls (finding new pages) versus refresh crawls (re-crawling known pages). If refresh crawls dominate and you are struggling to get new pages indexed, Googlebot is spending too much time re-crawling existing content instead of discovering new URLs.
Server Log File Analysis
For granular insight, server log file analysis is indispensable. By parsing access logs, you can see exactly which URLs Googlebot is requesting, how often, and how your server responds. Common findings include Googlebot repeatedly crawling parameter-laden URLs, crawling paginated archives extensively, or spending significant time on resource files (CSS, JS) rather than HTML pages.
Common Sources of Waste
The most common crawl budget sinks in order of prevalence are:
- Faceted navigation URLs: Filter combinations on e-commerce sites generating thousands of near-duplicate pages (e.g., /shoes?colour=red&size=42&brand=nike)
- Session IDs and tracking parameters: URLs with unique session tokens creating infinite duplicate versions of every page
- Infinite calendar or date archives: Calendar widgets or date-based navigation generating crawlable URLs into the far past or future
- Soft 404 pages: Pages that return 200 status codes but display “no results found” or empty content
- Duplicate content across HTTP/HTTPS or www/non-www: All four protocol-subdomain combinations being crawlable
- Internal search result pages: Crawlable site search URLs creating one page per possible search query
Robots.txt Strategies for Crawl Control
Robots.txt is your primary tool for preventing Googlebot from accessing entire categories of URLs. Unlike noindex directives, robots.txt stops the crawl before it happens, saving budget entirely rather than spending a crawl on a page you do not want indexed.
Blocking Low-Value URL Patterns
Identify URL patterns that consistently generate low-value pages and block them at the robots.txt level. Common patterns to block include:
# Block faceted navigation
Disallow: /*?colour=
Disallow: /*?size=
Disallow: /*&sort=
# Block internal search
Disallow: /search?
Disallow: /search-results/
# Block admin and system pages
Disallow: /wp-admin/
Disallow: /cart/
Disallow: /checkout/
Disallow: /my-account/
# Block tag pages with thin content
Disallow: /tag/Wildcard and Pattern Matching
Google supports limited pattern matching in robots.txt. The asterisk (*) matches any sequence of characters, and the dollar sign ($) indicates end of URL. These allow precise blocking:
# Block URLs with more than one parameter
Disallow: /*?*&*
# Block specific file types
Disallow: /*.pdf$
# Block paginated pages beyond page 5
Disallow: /blog/page/6
Disallow: /blog/page/7
# (continue as needed or use a wildcard approach)The Robots.txt and Noindex Conflict
A critical mistake is blocking a URL in robots.txt while also placing a noindex tag on that page. If Googlebot cannot crawl the page, it cannot see the noindex directive. The page may remain in Google’s index indefinitely, showing a snippet generated from anchor text and other external signals. If your goal is de-indexation, use noindex and allow crawling. If your goal is purely to save crawl budget and the page is not indexed, use robots.txt blocking.
Crawl-Delay Directive
While Googlebot does not officially support the crawl-delay directive in robots.txt, other bots (Bingbot, Yandex) do respect it. For Singapore businesses targeting markets where Bing or Yandex have meaningful share, setting an appropriate crawl-delay can prevent these bots from overwhelming your server.
Noindex, Canonical and Meta Robots Directives
When you need pages to remain crawlable (perhaps they serve users who navigate to them) but want to prevent indexation and consolidate signals, noindex and canonical tags are your tools.
Meta Robots Noindex
The meta robots noindex directive tells Google not to include a page in search results. Google will still crawl the page to see the directive, so this uses crawl budget. However, over time, Google tends to reduce crawl frequency for noindexed pages, so the budget impact diminishes.
Use noindex for pages that serve users but should not rank: paginated archive pages beyond page one, filtered category views, print-friendly page versions, and tag pages with minimal unique content.
X-Robots-Tag HTTP Header
For non-HTML resources or when you cannot modify page templates, the X-Robots-Tag HTTP header provides the same functionality. This is particularly useful for PDFs, XML feeds, and other resources you want to keep accessible but not indexed.
# In .htaccess or server configuration
<Files "internal-report.pdf">
Header set X-Robots-Tag "noindex, nofollow"
</Files>Canonical Tags for Signal Consolidation
Canonical tags tell Google which version of a page is the preferred one. For crawl budget purposes, canonicalisation helps by signalling to Google that duplicate versions are secondary, which over time reduces crawl frequency on the canonicalised variants.
However, canonicals are hints, not directives. Google may ignore them if other signals (internal links, sitemaps) contradict the canonical. Ensure consistency: the canonical target should be the version in your sitemap, the version receiving internal links, and the version returning a 200 status.
Combining Directives Strategically
For a typical e-commerce site, a layered approach works best: block parameter-heavy URLs with three or more parameters via robots.txt, apply noindex to two-parameter filtered views that users access, and use canonical tags on single-parameter sorted views pointing to the default sort order. This tiered strategy maximises crawl budget savings whilst maintaining user accessibility for common navigation paths.
Taming Pagination and Faceted Navigation
Pagination and faceted navigation are the two largest sources of crawl budget waste for content-rich and e-commerce sites respectively. Both require specific strategies that go beyond simple robots.txt blocks.
Pagination Best Practices
Google deprecated rel=”prev” and rel=”next” in 2019, leaving site owners without a formal pagination signal. Current best practices include:
- Self-referencing canonicals on each paginated page: Each page in the series should have a canonical pointing to itself, not to page one. Pointing all pages to page one risks de-indexing unique content on subsequent pages.
- “View all” pages where feasible: If the total content fits on a single page without severe performance impact, a “view all” page with canonical tags from the component pages is effective.
- Noindex beyond a threshold: For blog archives with hundreds of pages, applying noindex to pages beyond five or ten reduces index bloat whilst keeping early pages crawlable for link equity distribution.
- AJAX-based “load more” with progressive enhancement: Implementing infinite scroll or “load more” via JavaScript keeps the HTML pagination minimal whilst serving full content to users. Ensure Googlebot can still reach deep content through HTML links in the initial source.
Faceted Navigation Solutions
Faceted navigation on e-commerce sites creates a combinatorial explosion of URLs. A site with 10 colour options, 8 sizes, and 5 brands across 50 categories could theoretically generate 20,000 unique URLs from filters alone. Most of these pages contain duplicate or near-duplicate content.
The recommended approach is a whitelist strategy: determine which filter combinations have genuine search demand and unique content, allow those to be crawled and indexed, and block everything else. For a Singapore fashion retailer, “women’s dresses under $50” might have real search volume, whilst “women’s dresses size 8 colour beige brand X sorted by newest” does not.
Implementation options include:
- AJAX-based filtering: Apply filters via JavaScript without changing the URL, so no new URLs are created for Googlebot to discover
- Defined indexable combinations: Create clean, static URLs for high-value filter combinations (/women/dresses/under-50/) and use AJAX for all other filters
- Robots.txt blocking of parameter patterns: Block URLs containing filter parameters whilst maintaining a set of pre-rendered category pages
Working with an experienced web design team ensures faceted navigation is built with crawl budget in mind from the start, rather than retrofitted after indexing problems emerge.
Server Performance and Crawl Efficiency
Server response time is the single largest factor in crawl rate limit. Google has explicitly stated that faster servers get crawled more. This section covers the server-side optimisations that directly improve crawl efficiency.
Time to First Byte (TTFB)
Googlebot measures how quickly your server begins sending data after a request. A TTFB under 200ms is excellent; 200-500ms is acceptable; above 500ms triggers crawl rate reduction. For Singapore-hosted sites, ensure your server or CDN has edge nodes in the Asia-Pacific region, as Googlebot crawls from various global locations including data centres in Asia.
Common TTFB improvements include database query optimisation, implementing server-side caching (Redis, Memcached, Varnish), upgrading to faster hosting infrastructure, and reducing application-level processing on each request.
HTTP/2 and Connection Efficiency
Googlebot supports HTTP/2, which allows multiplexed connections. Enabling HTTP/2 on your server means Google can make multiple simultaneous requests over a single connection, reducing overhead and increasing effective crawl speed. Most modern servers (Nginx, Apache 2.4+, LiteSpeed) support HTTP/2 with minimal configuration.
Handling Crawl Spikes
After a major site update — launching new product lines, publishing a large batch of content, or restructuring URLs — Google may temporarily increase crawl activity. Your server must handle these spikes without degrading response times. Load testing with tools like k6 or Apache JMeter, configured to simulate Googlebot-like request patterns, helps identify capacity limits before they become problems.
CDN Configuration for Bots
Content delivery networks can either help or hinder crawl efficiency depending on configuration. Ensure your CDN does not serve stale cached pages to Googlebot after content updates, does not block Googlebot with WAF rules or rate limiting, and correctly passes cache status headers so Google understands content freshness.
Status Code Hygiene
Every 301 redirect Googlebot follows costs an additional request. Redirect chains (301 → 301 → 200) waste crawl budget proportionally. Audit your redirect rules to eliminate chains, update internal links to point directly to final destinations, and ensure 404 pages return genuine 404 status codes rather than soft 404s (200 status with “page not found” content).
Advanced Crawl Budget Techniques
Beyond the fundamentals, several advanced techniques can significantly improve crawl efficiency for large or complex sites.

XML Sitemap Optimisation
Your XML sitemap should be a curated list of pages you want indexed, not a dump of every URL on the site. Advanced sitemap practices include:
- Dynamic sitemaps: Generate sitemaps programmatically, excluding noindexed pages, redirected URLs, and pages returning non-200 status codes
- Sitemap segmentation: Split sitemaps by content type (products, blog posts, categories) to monitor indexation rates per section in Search Console
- Last-modified accuracy: Only update the lastmod value when page content genuinely changes, not on every server-side rebuild. Inaccurate lastmod values train Google to ignore the signal entirely.
- Priority and changefreq: Google has stated it ignores these values, so do not waste effort on them
Internal Linking for Crawl Distribution
Internal links are the primary mechanism through which Googlebot discovers pages. A well-structured internal linking strategy ensures crawl budget flows to important pages. Key principles include keeping important pages within three clicks of the homepage, using descriptive anchor text that signals page content, and avoiding orphaned pages with no internal links. Your content marketing strategy should incorporate internal linking as a core distribution mechanism.
IndexNow Protocol
IndexNow is a protocol supported by Bing and Yandex (not Google as of early 2026) that allows you to push URL notifications directly to search engines when content changes. For Singapore businesses with multi-search-engine strategies, implementing IndexNow reduces reliance on crawl budget for content freshness on supporting engines.
Hreflang and Multi-Language Crawl Budget
For Singapore sites serving content in multiple languages, hreflang tags create additional crawl demand as Google must verify the bidirectional annotations across all language versions. Ensure hreflang implementation is technically correct — broken hreflang causes Google to crawl repeatedly trying to resolve inconsistencies, wasting budget. Implement hreflang via XML sitemap rather than on-page tags to reduce HTML bloat and improve parsing efficiency.
Orphan Page Recovery
Pages that exist on your server but have no internal links pointing to them are orphan pages. Googlebot can only find these through external links or sitemaps, and they typically receive minimal crawl attention. Identifying and either linking to or removing orphan pages improves overall crawl efficiency. A comprehensive digital marketing audit will surface orphan pages alongside other technical issues.
Rendering Budget Considerations
For JavaScript-heavy sites, Google must not only crawl but also render pages. Rendering consumes separate resources in Google’s infrastructure, and there is evidence of a practical “rendering budget” distinct from crawl budget. Server-side rendering (SSR) or static site generation eliminates the rendering bottleneck, ensuring Google processes your content during the initial crawl rather than queuing it for later rendering.
Frequently Asked Questions
Does crawl budget matter for small websites?
For sites with fewer than a few thousand pages, crawl budget is rarely a concern. Google will typically crawl all pages without issue. However, even small sites can waste crawl budget through misconfigured parameters, duplicate content, or excessive redirect chains. The principles of crawl budget optimisation — clean URL structures, fast servers, proper canonicalisation — benefit sites of any size.
How can I check my current crawl budget in Google Search Console?
Navigate to Settings > Crawl stats in Google Search Console. This report shows total crawl requests, average response time, and response code distribution over the past 90 days. While it does not show an explicit “crawl budget” number, the daily crawl request volume is the practical measure of your effective crawl budget.
Should I use robots.txt or noindex to manage crawl budget?
Use robots.txt when you want to prevent crawling entirely and save budget. Use noindex when pages need to be crawlable (for user access or link equity flow) but should not appear in search results. Never use both on the same URL, as robots.txt blocking prevents Google from seeing the noindex directive.
How does server speed affect crawl budget?
Server speed directly determines the crawl rate limit — the maximum speed at which Google will crawl your site. Faster servers with lower response times receive higher crawl rate limits, effectively increasing crawl budget. Reducing average response time from 500ms to 100ms can increase crawl volume several-fold.
What is the difference between crawl budget and index budget?
Crawl budget refers to how many pages Google will request from your server. Index budget is an informal term referring to how many pages Google will keep in its index. A page can be crawled without being indexed (if it has thin content, noindex, or quality issues). Optimising crawl budget ensures important pages get crawled; content quality and relevance determine whether they get indexed.
How do faceted navigation URLs waste crawl budget?
Faceted navigation creates unique URLs for every filter combination. A site with 10 filters each having 5 options can generate millions of URL combinations, most containing duplicate or near-duplicate content. Googlebot attempts to crawl these URLs, consuming budget that should be spent on unique, valuable pages. Blocking or AJAX-loading filter URLs eliminates this waste.
Does Google crawl budget affect ranking directly?
Crawl budget does not directly affect ranking. However, if important pages are not crawled or are crawled infrequently, Google may not index them or may not pick up content updates promptly. This indirectly affects ranking by delaying the recognition of new or improved content. For large sites, crawl budget inefficiency can meaningfully impact overall organic visibility.
How often does Google recalculate crawl budget?
Google continuously adjusts crawl rate based on server responsiveness and other signals. There is no fixed recalculation schedule. Improvements to server speed typically result in increased crawl rates within days to weeks. Changes to crawl demand (new content, increased authority) can shift crawl patterns over a longer period.
Can I increase my crawl budget in Google Search Console?
You cannot directly set a crawl budget. In the legacy version of Search Console, there was a crawl rate setting, but this only allowed you to reduce the rate, not increase it. The most effective way to increase crawl budget is to improve server response times, reduce URL bloat, and produce high-quality content that generates crawl demand.
How do XML sitemaps affect crawl budget?
XML sitemaps help Google discover URLs and understand which pages you consider important, but they do not increase crawl budget. Submitting a sitemap with 100,000 URLs does not mean Google will crawl all 100,000 faster. However, a well-maintained sitemap with accurate lastmod dates helps Google prioritise its crawling, ensuring budget is spent on genuinely updated content. A professional Google Ads and SEO team will ensure your sitemaps and crawl infrastructure work together for maximum visibility.